































Integration of Large AI Model with SLAM-Based Mapping and Navigation

Large AI Model–Driven Embodied AI Applications


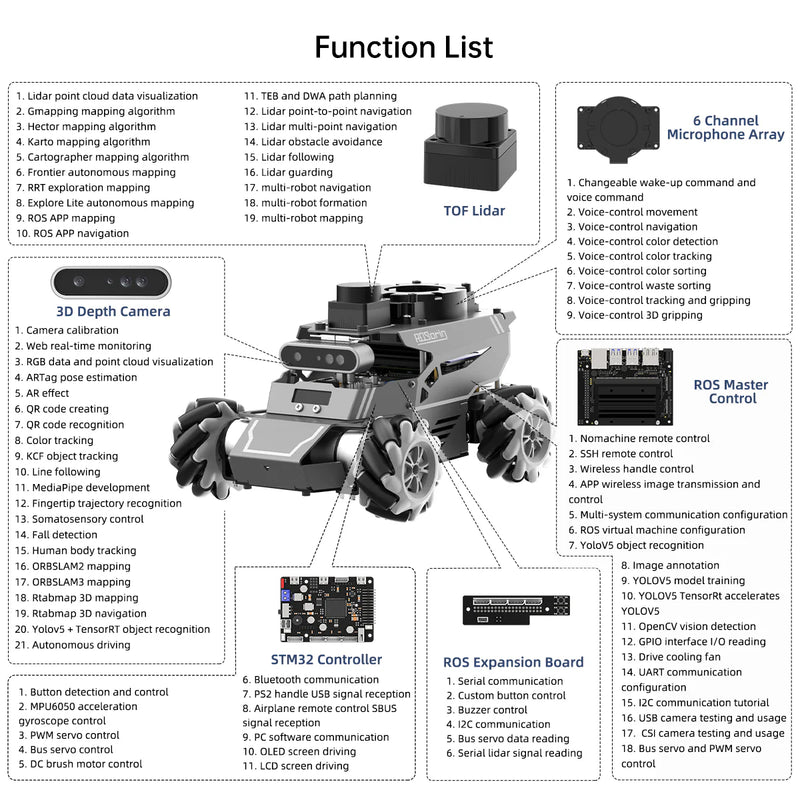
Key ROS Features









Large AI Model Robot Comparison











![]()

Wrapped Rear Tail ShellIt can effectively protect the PCB circuit and magnetic ring at the end of the motor from external influences, effectively improving the safety and service life of the motor. |

Permanent Magnet Brushed MotorThe permanent magnet DC motor has fast starting response speed, large starting torque and smooth speed change. |

High-precision Magnetic EncoderThe permanent magnet DC motor has fast starting response speed, large starting torque and smooth speed change. |
 Adapt to Various ScenesThe low speed of 1:90 ratio and the high torque of 15kg.cm enable the motor to adapt to car chassis made of various materials. |
 Hall Encoder Geared MotorThe Hall speed measurement code disc is a speed measurement module that utilizes Hall sensor encoders. Equipped with a strong magnetic disc, it generates AB phase output pulse signals, enabling the detection of motor rotation direction and speed. |
 Mecanum Wheel
|

Specification Parameters
| Machine Model | Mecanum Chassis Version (Standard) | Ackerman Chassis Version (Standard) | Four-Wheel Differential Chassis Version (Standard) |
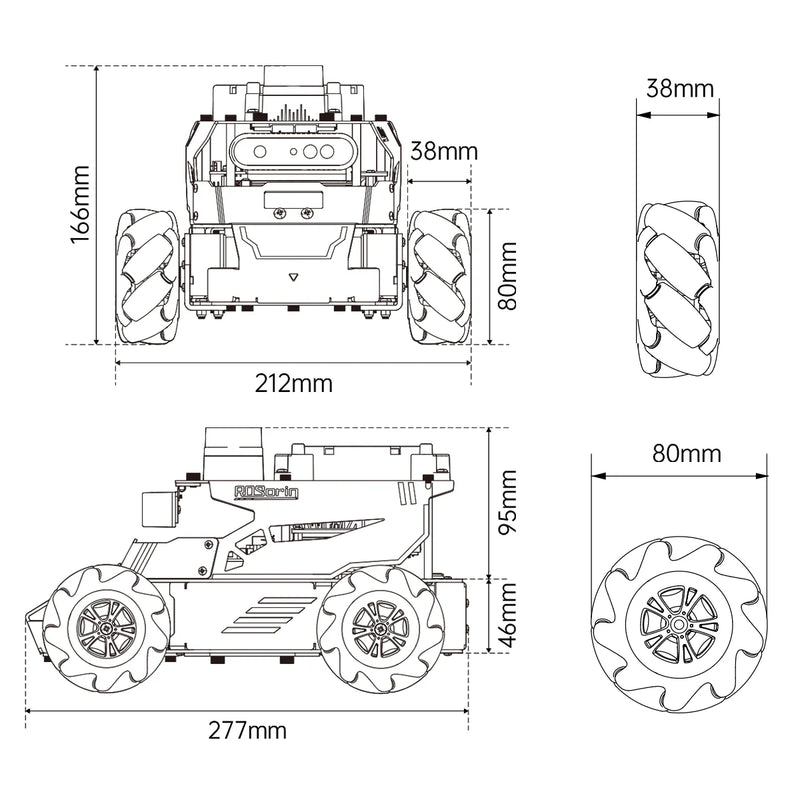
| Product Dimensions | 277 × 212 × 166 mm | 277 × 204 × 169 mm | 277 × 204 × 166 mm |
| Product Weight | 2.66 kg | 2.15 kg | 2.26 kg |
| Motor | 520 metal gear reduction motor | ||
| Encoder | High-precision AB quadrature encoder | ||
| Chassis Material | Full-metal aluminum alloy chassis with anodized finish | ||
| ROS Controller | Jetson Nano / Jetson Orin Nano / Jetson Orin NX / Raspberry Pi 5 board | ||
| Multi-function Expansion Board | STM32 ROS robot controller, Jetson multi-function expansion board | ||
| Control Method | App control, wireless controller control, PC software control | ||
| Depth Camera | Aurora 930 Pro 3D depth camera | ||
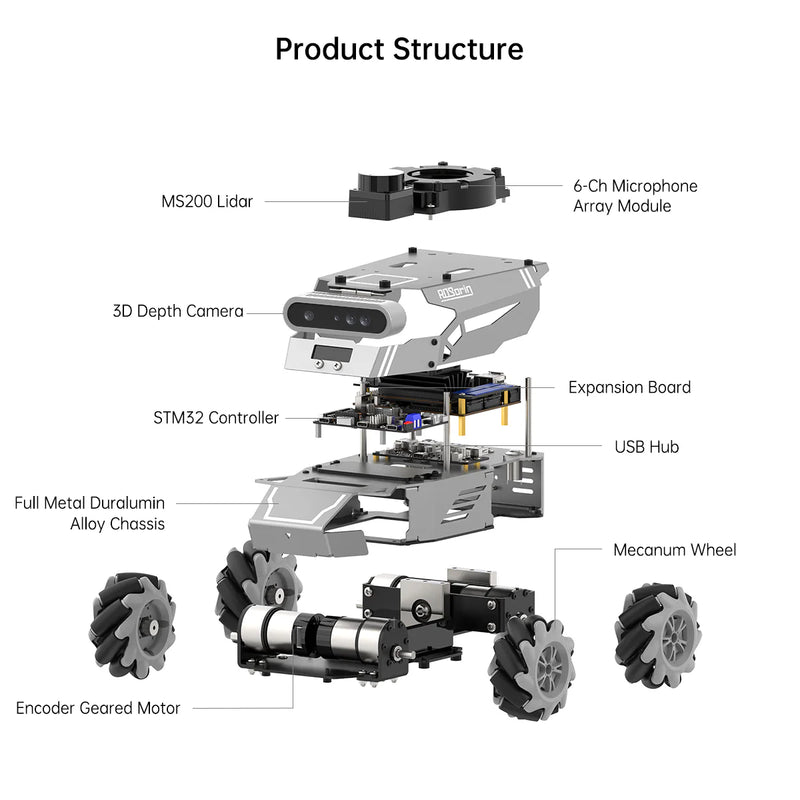
| LiDAR | MS200 TOF LiDAR | ||
| Battery | 11.1V 6000mAh 3C lithium battery | ||
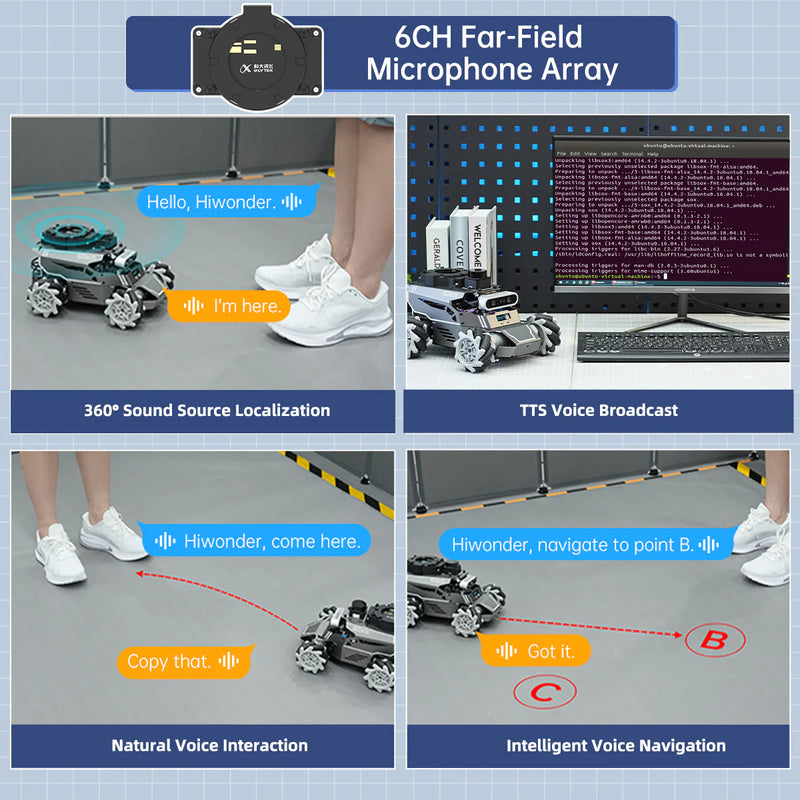
| Audio / Pickup | WonderEcho Pro AI voice interaction box / 6-mic array module | ||
| Operating System | Ubuntu 18.04 LTS + ROS Melodic / Ubuntu 22.04 / ROS2 Humble | ||
| Software | iOS / Android App | ||
| Communication Method | WiFi / Ethernet | ||
| Programming Tools | Python / C / C++ / JavaScript | ||
| Storage | 64G TF card (Jetson Nano, Raspberry Pi 5) 128G TF card (Jetson Orin Nano) 128G SSD (Jetson Orin NX) |
||
| Servo Model | LD-1501MG | ||
| Map / Props | AI sandbox map for autonomous driving, traffic lights, road signs | ||
| Tutorials | Comprehensive tutorials, ROS source code, system image, supporting software | ||
Dimensional Diagram

ROSOrin Starter Packing List

ROSOrin Standard Packing List

ROSOrin Advanced Packing List

ROSOrin Ultimate Packing List

Tutorials
https://docs.hiwonder.com/projects/ROSOrin/en/jetson-orin-nano-version/
Want to buy in bulk?
Custom Requirements?
Discussion Forum
Feel free to ask questions, share tips or report issues.